One of the most important aspects of our approach to building AI features is ensuring we use your data ethically. This article might get boring or technical, but some people really want to know these details.
“Your data” feels so sterile, so generic. Instead of calling it your data, let’s call it your stories, your creations, your ideas, your brainchild … children … brainchildren? Maybe let’s call it your “story data.”
We’re determined to be good stewards of your story data because we are also caring for our own at the same time.
How AI in Plottr Handles Your Story Data
Now, when you use the forthcoming AI features in Plottr, we make it very clear that you’re about to use AI, so there’s no way it’s going to happen without you knowing it.
And when you do use one of the AI features, Plottr makes a request to one of our servers and that request is carrying some of your story’s data.
I can detail what that entails (characters, scenes, etc.), but for now, it’s only important to know that some of your creation is flying through the Internet to our servers (whether you have Plottr Pro —which is all in the cloud — or not)
Our servers get a prompt ready with your story data and send that to the LLM model (the AI).
Will Plottr Use My Story Data to Train AI?
When you talk to an LLM this way — from computer to computer instead of chatting with it like ChatGPT — your data isn’t stored in the LLM and it isn’t used to train the LLM at all.
That may change and we have no control over AI platforms’ policies, but for now, here’s what OpenAI says about using their API to use ChatGPT (an API just means two computers talking to each other). And that’s the way we are talking to ChatGPT, through the API.
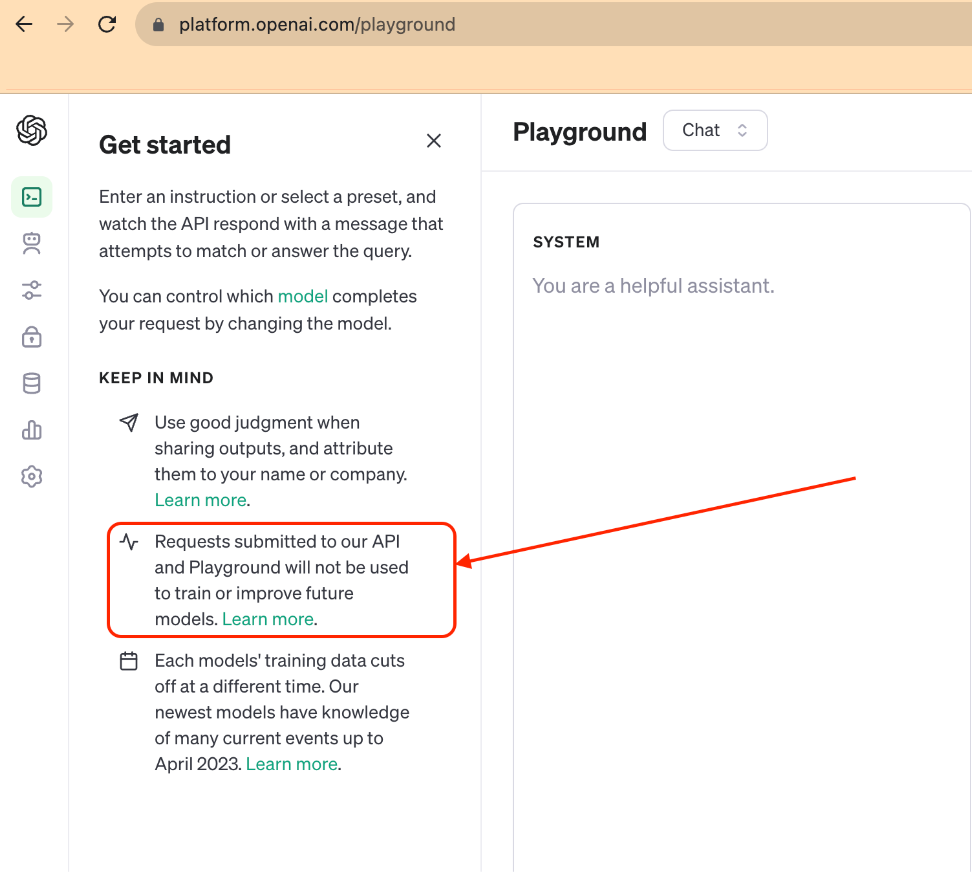
So once we get a response back from ChatGPT with the results of your prompt, we store some statistics about it (how many words in the prompt, how many words in the answer, etc.) and then we send it directly back to the device that you were working on.
We Don’t Store Your Story Data Beyond Plottr Pro
We don’t store the prompt, nor the response, nor any of your story data. If you’re on Plottr Pro, your story data is safely stored in our cloud anyway, but if not, it’s only temporarily on our servers and then discarded.
We don’t analyze your story nor the LLM’s response. We don’t use your story data to train an LLM of our own. We don’t have an LLM of our own. We are just using the available ones out there like OpenAI, Claude, etc.
What About Risks to My Story Data?
There are always risks with digital data, and it’s a compromise that we’ve all accepted by using computers and the Internet. That’s nothing new for Plottr AI and your data.
It’s like when humans invented fire, or the concept of double-edged swords. Fire has improved the world for millennia, but it also burns people every day. And we all know what happens with double-edged swords 😏
Luckily we’ve built the AI features into Plottr in such a way that you don’t have to use them at all if you don’t want to. They’re not forced upon you, and it’s very clear when you’re using them.
So to summarize:
- Plottr doesn’t have its own LLM
- We’re relying on existing LLMs
- We’re using the API so LLM models don’t train themselves with your story data (but we have no control over that long-term)
- Your story data is briefly transmitted on our servers but then gets discarded once you get your AI-generated output (unless you’re on Plottr Pro)
- We’re not analyzing or reading your story data
On that third point: We have no say over OpenAI’s policy around how it stores data, but if it changes in the future we’ll let Plottr users know so you can keep using AI features fully informed (or opt not to use them, as you prefer).
Like I said at the outset of this post, this wasn’t going to be the most fun or interesting, but it’s important for everyone to know how we’re treating your data and how it will be used for upcoming AI features, if you choose to use them.
We’re trying hard to be good stewards of your story data because we are also caring for our own story data and it’s precious to us, just like it is to you.
Cameron Sutter,
Plottr Founder and CEO

About Cameron
Cameron Sutter is a sci-fi/fantasy author and the inventor of Plottr – the popular visual story planning software. He’s escaped death by explosion, rock slide, disease, and car accident. He loves doing funny accents for his kids, but believes his life’s mission is to serve writers. He lives near Oklahoma City with his wife, six kids, and too many pets.





4 thoughts on “Plottr AI and Your Data”
All existing LLMs were trained from stolen data in the first place. There is no ethical use of any current model, plain and simple. If you were actually worried about this, you would keep your product far away from them.
As it stands, I’m sorry that i zany recommend plottr to anyone, now, and will have to retract my recommendations from the past. I’m glad i only ever got the stand alone version, and i won’t be updating it so long as there’s any avenue open to an LLM.
i don’t know why it’s so difficult to understand that OpenAI and all thier ilk consistently lie and steal data from every source they can, but that is literally what they have done from thier inception. There are *zero* real user protections for anything that touches thier model. You’re deluding yourself if you think any differently.
God this is disappointing.
Thanks so much for expressing your concerns about AI tools and LLM models in general. You’re not wrong and I totally hear you. We’re not taking a hard stance for or against LLMs honestly. It’s a murky, complex subject.
First let me just say that these features will be completely optional and turned off by default. You will have to purposefully engage the LLM features and you’ll know when it’s about to be used. There won’t be any surprises there, and if you don’t click the button each time you want to use the LLM feature, our system never calls out to an LLM model.
Secondly, your data is never used to train any model because we’re using the API.
Lastly, you’re probably not wrong about what OpenAI has done. What if we use Claude? And what about Google and Facebook that have been selling your data for years? I have the same hangups with them. I don’t trust them, I don’t like them, but to operate certain things in my life, I kind of have to use them.
That’s not to be argumentative. I just know it’s a not a cut-and-dry topic and we’re trying to navigate this world-changing technology the best way we can.
I know we’ll make mistakes. That’s how we learn. There’s no other way unfortunately. Hopefully you all will give us some grace as we find our way and stumble along the path.
Actually, it’s not so murky. You simply stand for your beliefs and avoid things that aren’t ethical, even if that means giving up technological conveniences. (But in reality, is generating words and ideas that aren’t your own a convenience? or just a cop-out? Should one really be writing if they can’t first think?) Facebook and Google *aren’t* mandatory tools for living or achieving success, so if anything, that just confirmed to me that you’re refusing to face the serious consequences of supporting such “tools.”
It’s all very clever (and condescending) to compare AI to fire or double-edged swords, but it’s ultimately smoke and mirrors. The level of harm AI does to the creative industry and the environment as a whole every time you access it is insurmountable. You can’t avoid the destruction, no matter how little of it you use.
And on a human existence/ psychological side of things, these are all “conveniences” that we could get from basic human interaction and reflection. Need to generate an idea? Talk it through with a friend for 5 minutes. Don’t have a friend? Go journal or people watch, again, for a few minutes. Need to edit your words? Wow, there’s people trained and happy to do that! It even helps them live! Not to mention, editing and grammar are easy things to study and practice throughout your writing process.
The human mind will always be faster, more original, and more capable than AI, if you’re willing to spend the handful of minutes it takes each day to exercise it. You’re not meant to have all the ideas or all the problems solved. That’s part of the writing journey and it gets solved through experience. We don’t need everything to be instantaneous. If we forget how to imagine and think, all we are doing by accessing AI is making ourselves weaker and weaker writers, more focused on the bottom line than on telling our story or making a real impact on the world. There’s no more important impact with our writing than on our own mind as we experience the journey of human thought.
I will never support a site or product whose creator sidesteps the real issues using divisive diction and downplays how dangerous their actions are. You have to willfully blindfold yourself to believe that offering the option of AI generative tools is beneficial to anyone other than your pocket. There is a wake of destruction that follows anyone whom not only refuses to take a firm stand against generative AI but whom actively supports and implements it.
Hi Ash, thank you for sharing your point of view on AI. I’ll share this feedback with Cameron. Just to say that as a team we have many discussions around LLMs and how best to use them responsibly so that this is done as ethically as possible (given the important concerns you raised), and in a way that puts serving writers and storytellers first.
We hear from many Plottr fans who are frustrated that we don’t yet have generative or productivity-focused AI features in Plottr. Since LLM-based tools are fairly ubiquitous across devices and apps at this point, many people have embraced them and even expect them. So we are aware that it’s a divisive issue with strong feelings on both sides, for and against. We’re listening and we do care.